Meet NetActuate at All Things Open 2025 in Raleigh Oct 13-14!
Explore

Meet NetActuate at All Things Open 2025 in Raleigh Oct 13-14!
If one location suffers outage (power failure, fire, etc.), anycast can automatically reroute traffic to a backup site without interruption.

Companies struggle with disaster recovery due to growing infrastructure complexity, hybrid cloud dependencies, and data sprawl across regions and platforms. Ensuring rapid failover, data integrity, and minimal downtime is difficult without continuous testing and automation. Many organizations lack real-time replication, standardized processes, and clear recovery objectives. Budget limits, legacy systems, and cybersecurity threats further hinder effective, resilient recovery strategies.
If a company’s location is impacted for any reason, anycast can seamlessly reroute traffic to a backup site with no interruption.
Utilizing anycast, if a server at one location goes down because of a power outage, fire, or other disaster; traffic can be seamlessly rerouted at the network level to a backup site. This makes anycast an excellent addition to any disaster recovery toolkit.
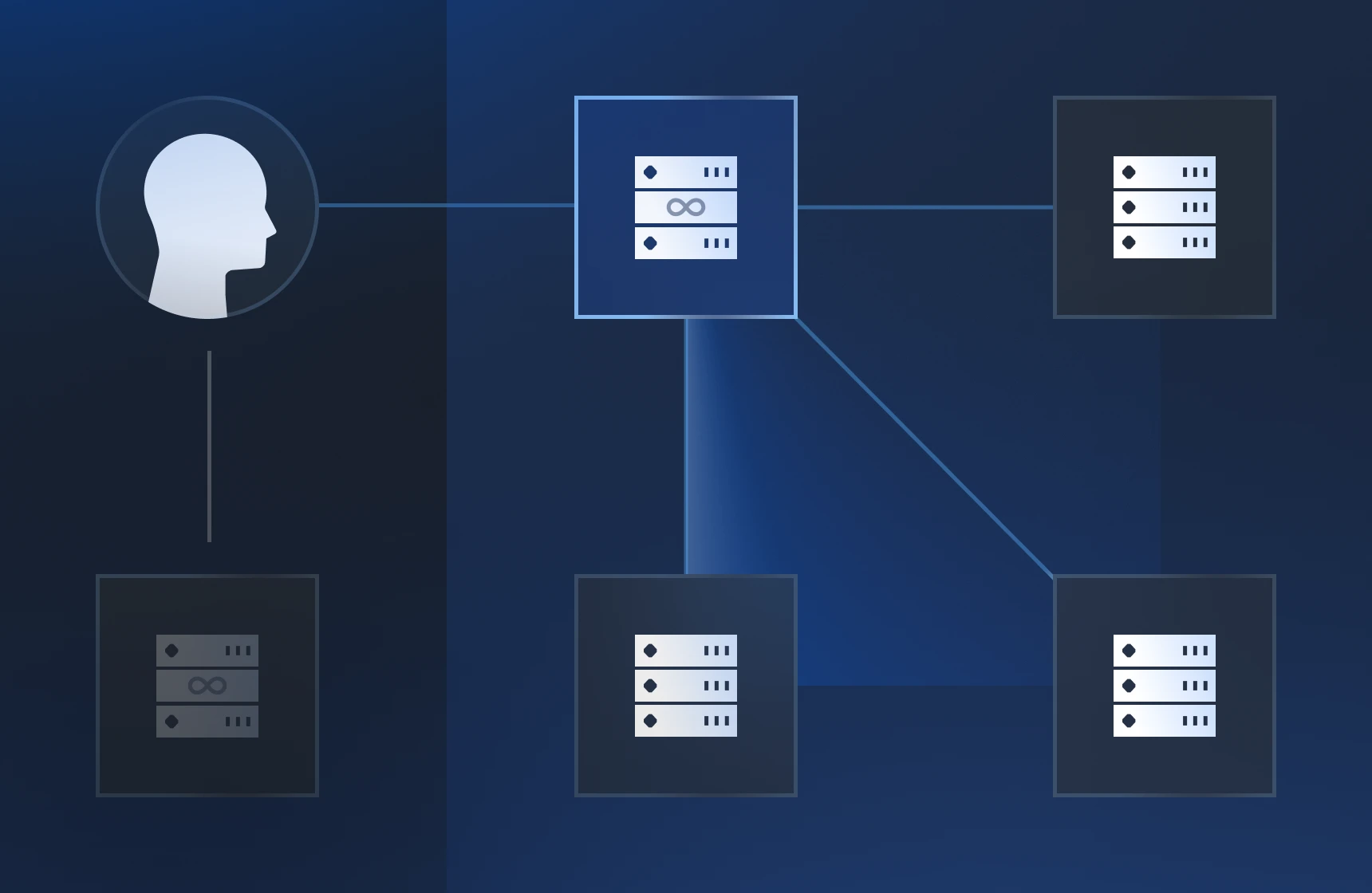
Let’s say we have an anycasted A+B disaster recovery deployment, where server A is being backed up regularly to server B in an alternate location. Normally, the anycast announcement routes all traffic to server A using one IP address.

However, if server A crashes, is attacked, or is even destroyed in a natural disaster, the anycast announcement can be quickly updated to reroute traffic to server B. Because the IP address doesn’t change, and the rerouting happens at the network level, the impact to end users is minimal.
For businesses that don’t have the capacity for real or near time server synchronization, anycast can be used to minimize business impact in the event of a failure or disaster of any kind in your primary location.



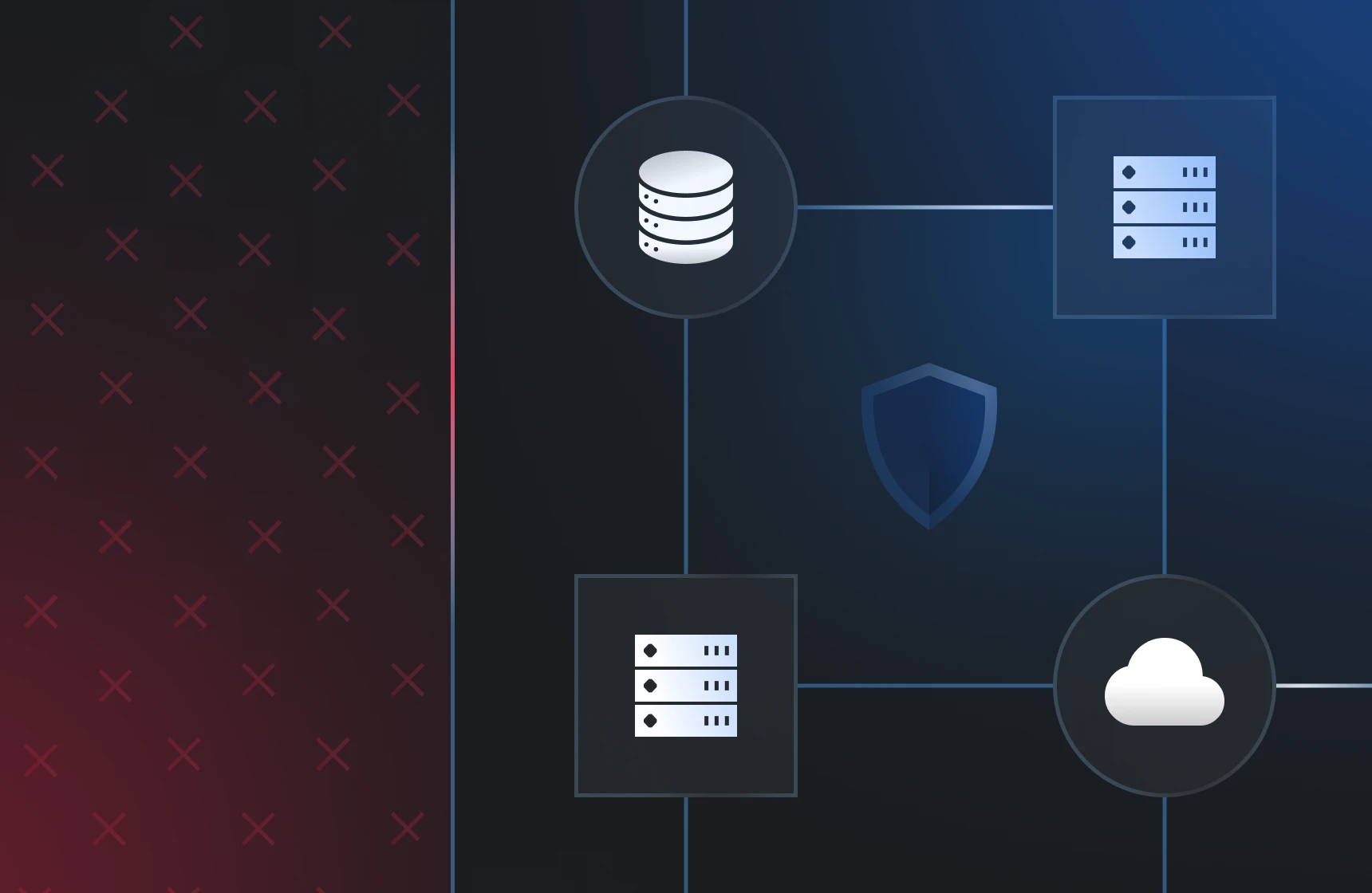
Benefits include automatic fail-over at the routing level, global geographic diversity, simplified endpoint addressing (one IP), and improved resilience during regional outages or large-scale incidents.
Deploy geographically diverse nodes all advertising the same IP, tie routing announcements to health status, ensure health-checks trigger route withdrawal, and test fail-over scenarios (e.g., site failure) regularly.
Track metrics like latency, traffic shifts (AS-paths), routing changes, node availability, fail-over time. Conduct drills: disable a node and verify traffic reroutes cleanly. Document which node is handling traffic from different regions.

Deploy across 45+ global locations on one of the world’s largest networks, engineered for performance, resiliency, and efficient scaling without the risk of downtime or runaway costs.